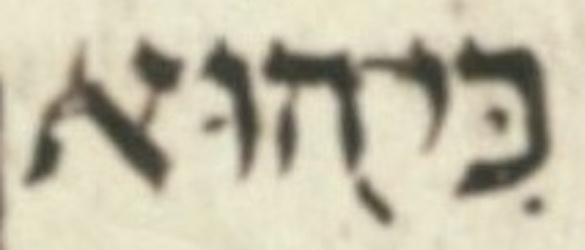
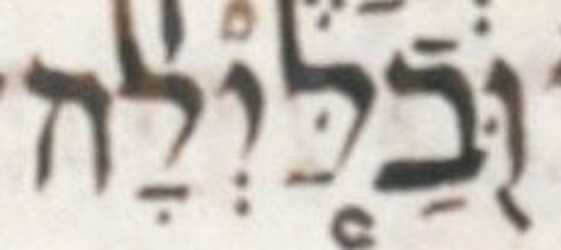
Sefaria.org
Sefaria.org
| Changes |
Proposed changes to the textHow to suggest a text changeChange summary |
Caution: The Hebrew text of the OSHB Verse site is not the UXLC text; the text is from WLC 4.20 (25 Jan 2016). To see if a particular verse in OSHB Verse differs from that of the UXLC click on the centered Unicode/XML Leningrad Codex [] title of the UXLC Book page and see if the verse appears in the corrections table. If the verse doesn't appear in the corrections table, the texts are the same and the diagram is correct.
|
Daniel Holman, of Tomah, Wisconsin, USA,
has completed his first pass through the Tanach.
His effort started with UXLC 1.5 in July 2022
and produced 772 corrections up to the current text.
These corrections represent about 75% of the UXLC corrections to date!
|
|
|
|
|
Sefaria.org |
Sefaria.org |

|
|
|
|
| Hints about site features are included. These hints appear in blue boxes (like this) and disappear after a few (5) viewings of the site. To restore these hints, click the build number at the lower, right corner of the Home page and reload the site. |

|
|
Sefaria.org |
Suggestions for new notes are appreciated.The previous method of hovering the cursor over the note symbol has been retained; however, for selected notes, clicking on the note brings up a popup window giving a detailed note specific to the noted text. Currently, all notes in Hebrew text are clickable and produce detailed notes. For example, see Jeremiah 44:19. Hovering on the note t produces the general note text "Transcription uncertain. Examine the LC image for other possible readings." Clicking on the t brings up a detailed note specific to this text in a popup window. In this case, the note shows an image of the LC containing the word.
| 27.6 |